Construído em 1909 para ser o navio mais luxuoso e seguro de sua época, o Titanic teve sua existência encurtada, naufragando 2 anos depois ao se chocar com um iceberg no oceano Atlântico. Com cerca de 1500 pessoas, é considerada uma das maiores tragédias da humanidade. A história do transatlântico é retratada em livros, filmes e documentários e seus destroços até hoje são visitados por equipes de explorações.
O mais acessado desafio do site de data science Kaggle, é justamente sobre o famoso Titanic. Nele é fornecido duas bases de dados sobre 1309 pessoas que estavam a bordo do Navio no momento do acidente. Uma com 891 registros contendo a informações sobre cada indivíduo e se ele sobreviveu ou não. E outra com 418 registros sem a informação de sobrevivência.
O desafio consiste em encontrar padrões entre as características que levem a pessoa a sobreviver ou não, construindo assim um modelo que seja capaz de prever se uma pessoa sobreviveu ou não, apenas se baseando em suas características.
Não há restrições quanto a linguagem ou software para realizar o desafio. No meu caso utilizei Python e o Google Colaboratory como IDE. Nesse post faremos uma breve exploração na base de dados para compreender melhor os dados e os fatores ligados à sobrevivência ao acidente.
Para quem quiser um passo-a-passo de como fazer o desafio, neste Link há todo o código que utilizei no processo. Recomendo também o post do Paulo Vasconcelos repleto de dicas super bacanas.
Bom, vamos as nossas análises. Temos os seguintes dados no dataset:
Após um tratamento que envolveu: remoção de dados irrelevantes, preenchimento de dados faltantes e categorização de dados, e gráficos gerados com Seaborn, obtemos as seguintes análises:
De um total de 891 passageiros desse dataset, 342 sobreviveram e 549 morreram no acidente.
Relação por classe:
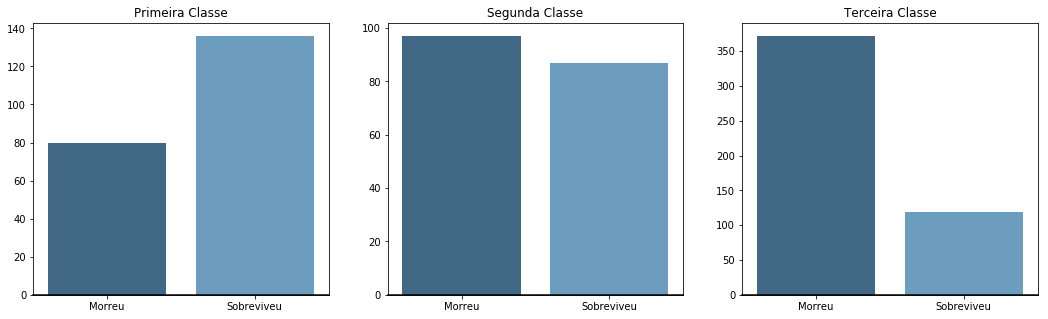
Aqui podemos notar que a classe em que o passageiro viajava é um fator que influencia na sobrevivência. Passageiros que viajam na primeira classe têm mais chances de sobreviver do que os da segunda, que por sua vez, têm mais chances que os da terceira.
Relação por gênero:

Pessoas do gênero feminino sobreviveram mais do que pessoas do gênero masculino.
Relação por faixa etária:
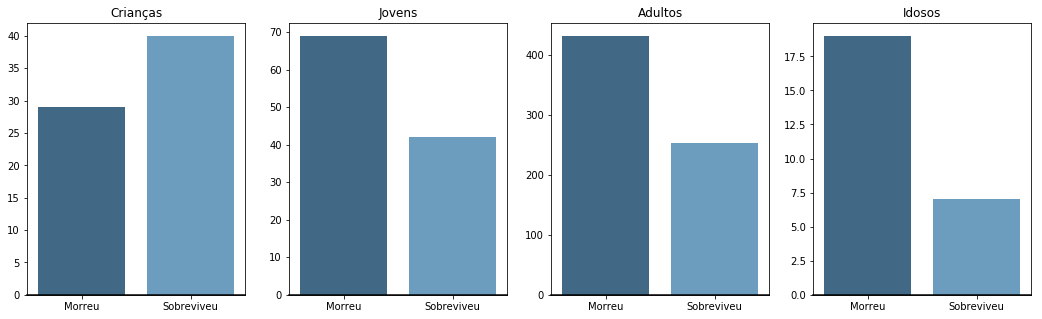
Podemos notar que apenas as crianças tiveram o número de sobreviventes maiores do que o de mortos. Os adultos eram maioria, e em números, foram os que mais sobreviveram e também os que mais morreram.
Relação por porto de embarque:
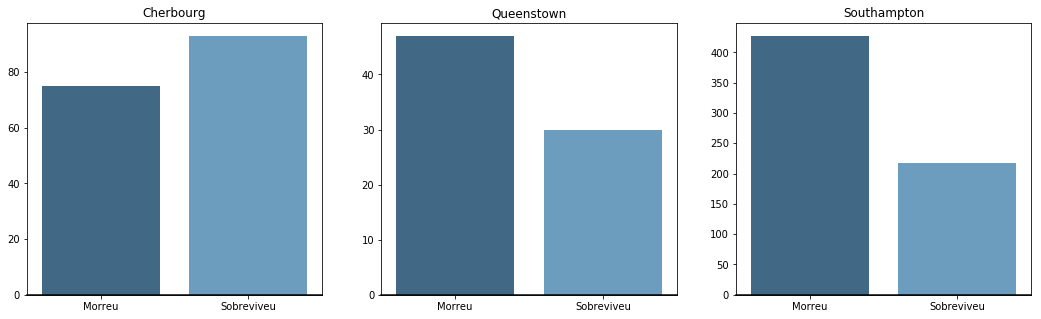
A Maioria dos passageiros embarcaram em Southampton, nos EUA, tendo os maiores números de mortos e de sobreviventes. Apenas os passageiros que embarcaram em Cherbourg na França, possuem mais chances de sobreviver do que morrer.
Matriz de correlação:
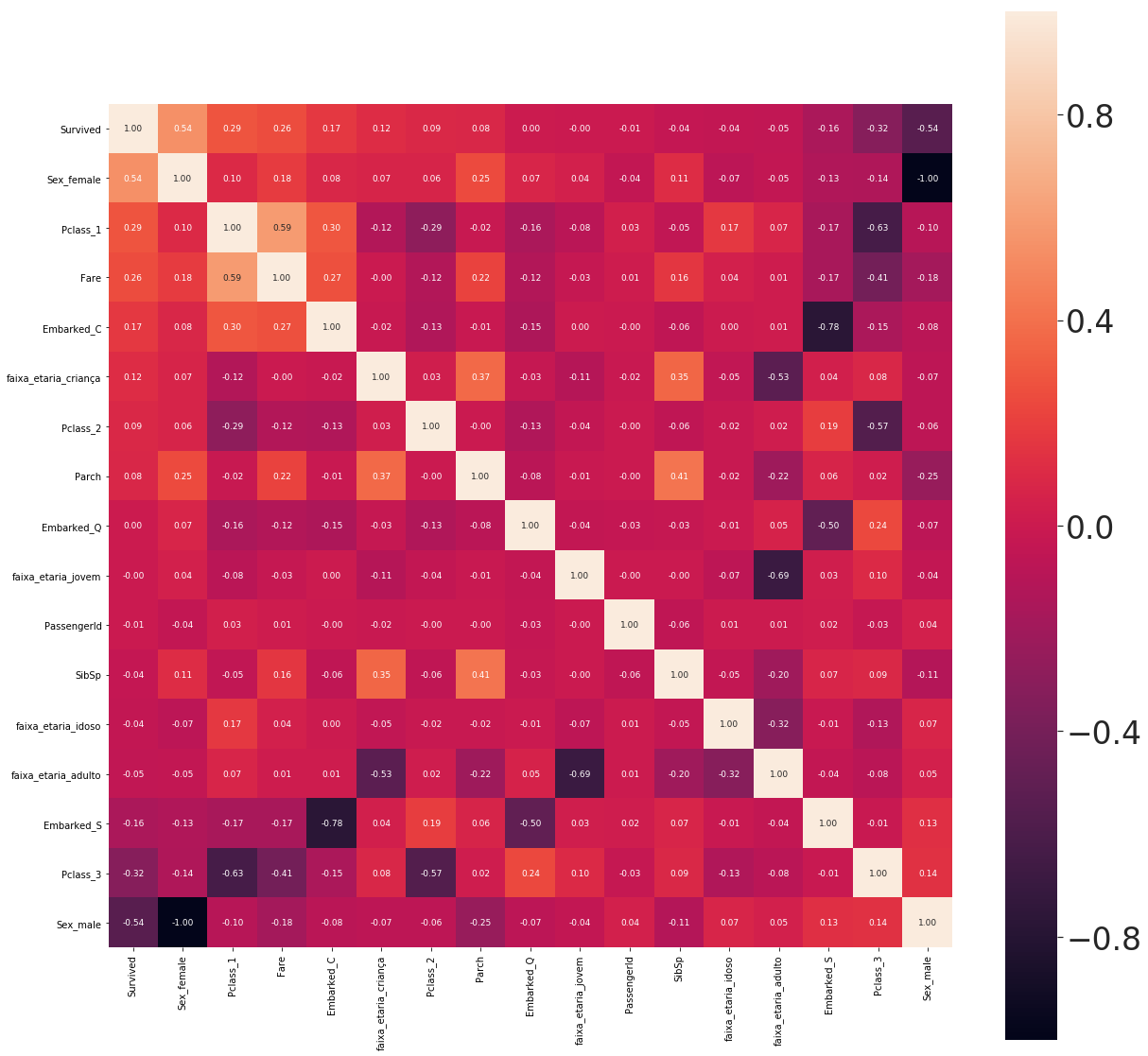
Ao gerarmos uma matriz de correlação das variáveis
Se fossemos determinar 5 valores que aumentaria as chances de um passageiro sobreviver com base nessa matriz, eles seriam:
Ser do gênero feminino, viajar na primeira classe, pagar valor alto na passagem, embarcar em Cherbourg e ser criança.
Em contrapartida, os 5 valores que aumentaria a possibilidade do indivíduo não sobreviver são:
Ser do gênero masculino, viajar de terceira classe, embarcar em Southampton, ser adulto ou idoso.
Pra quem quiser, segue o link do Colaboratory com o código completo, nele tem todo o processo de limpeza utilizando Pandas e também a construção de um modelo preditivo de árvore de decisão.
06-02-2019 | Update:
Pra quem quiser, segue o link também do Github com o código e o dataset disponível para baixar. ;)