No dia 13 de março de 2019, o Flamengo recebeu a Liga Deportiva Universitaria de Quito (LDU) no Maracanã para o segundo jogo da fase de grupos da Copa Libertadores da América. Sendo essa partida, a primeira da competição que o clube Rubro-negro joga em casa, com o apoio de sua torcida. E que torcida, 62.440 presentes no estádio.
Infelizmente, eu não pude estar presente. Mas como bom rubro-negro que se preze, acompanhei do início ao fim. Todo jogo gera um grande volume de interações nas redes sociais, então aproveitei a oportunidade coletar dados no twitter sobre o jogo e produzir uma análise quantitativa.
Foi um jogo emocionante, vitória do Rubro-Negro com direito a tudo: gols, faltas, cartões, defesa de pênalti… Contudo, não vou entrar muito em detalhes futebolísticos, falando como o Flamengo maltrata meu coração... Vamos a nossa análise de tweets. ;)
Para a coleta, utilizei a IDE Jupyter Notebbok rodando um código em Python que armazena os tweets em um banco de dados MongoDB. Esse código está disponibilizado no post anterior aqui do blog.
Como o objetivo do blog não é só compartilhar análises e códigos, mas também experiências, é importante mencionar que esse método de coleta não se mostrou ideal para essa tarefa. Eu já havia testado antes em outras coletas de tweets, mas o volume produzido em alguns momentos do jogo fez a aplicação parar, sendo necessário botar para “rodar” novamente a célula de coleta.
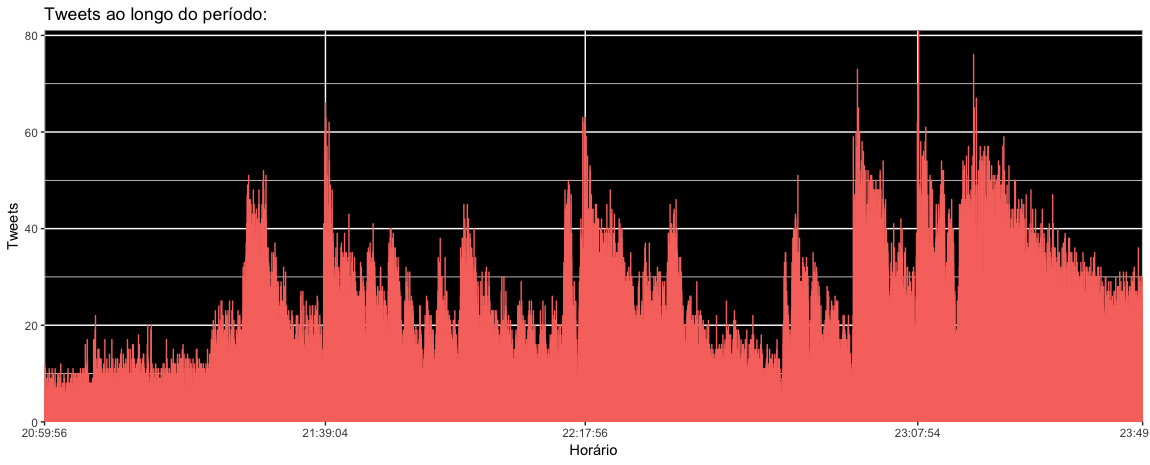
Os momentos de pico foram: apito inicial, gols, pênalti e apito final. Nesses momentos, como disse, precisei reiniciar a célula e por isso perdi a coleta de tweets por alguns segundos. Mesmo com esses problemas a coleta gerou um base de dados significativa e julguei que valia a pena não descartá-la e prosseguir para a etapa de análise. Desse processo, fica o aprendizado, e para as próximas estou desenvolvendo uma solução de extração mais robusta com Spark.
A análise foi feita com linguagem R na IDE Rstudio. Aqui no post trarei apenas números e algumas visualizações. O código completo da análise estará disponível em um link no final do post.
A coleta foi iniciada cerca de 30 minutos antes do jogo(20:59:56) começar e 30 minutos após o término(23:49:57) da partida. A duração total do processo de coleta foi de 2 horas, 50 minutos e 1 segundo.
Foi usado como parâmetro de coleta a seguinte lista de palavras: 'Flamengo', 'flamengo', 'mengo', 'Mengo', 'Mengão','mengao','Mengao','#CRF'. Ou seja, tweets que continham ao menos uma dessas palavras foram recuperados pelo nosso processo.
Ao final ficamos com uma base de dados de 183.027 tweets (falei que o volume era grande), produzidos por 77.225 usuários. O que nos dá uma média de 2.37 tweets por usuário. Do todo, 66.991 são tweets originais e 116.036 são retweets ou citações de outros.
Após essas trivias numéricas, vamos a algumas visualizações.
A distribuição dos 183.027 tweets ao longo das 2 horas e 50 minutos de coleta ficou assim:
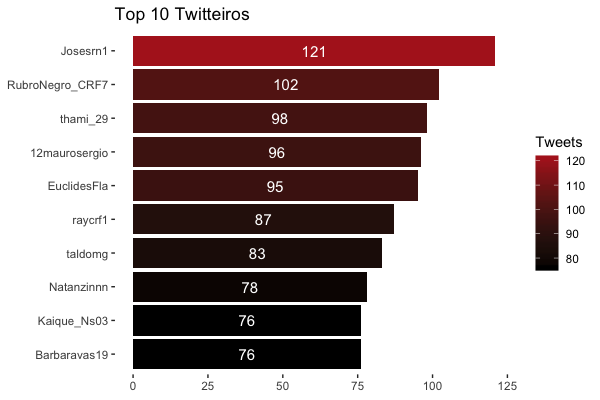
Entre os 77.225 usuários, os 10 que mais twittaram foram:
125 usuários possuem contas verificadas pelo Twitter (personalidades, jornalistas e veículos de comunicação), entre eles, o Top 10 foi:
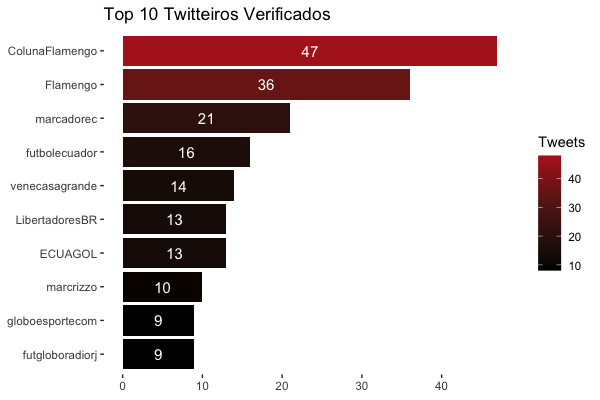
Destaque para o blog Coluna do Flamengo que interagiu mais na rede social que o próprio clube.
É claro que os nomes dos jogadores e técnico sempre são lembrados, da equipe da Gávea, os mais citados foram:
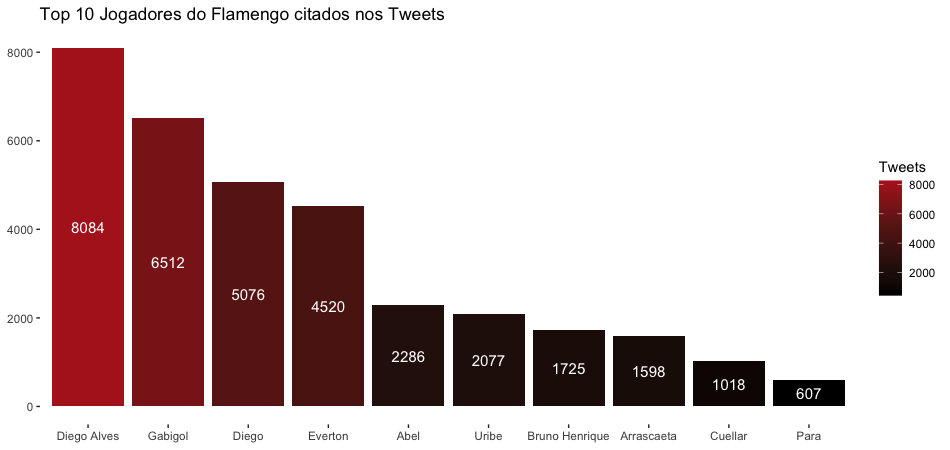
Ao pegar um pênalti quando o jogo ainda estava 1X0, Diego Alves evitou o empate equatoriano, foi destaque na partida e no twitter. Vale também citar o técnico Abel, ele foi mais lembrado que muitos jogadores e ficou na quinta posição.
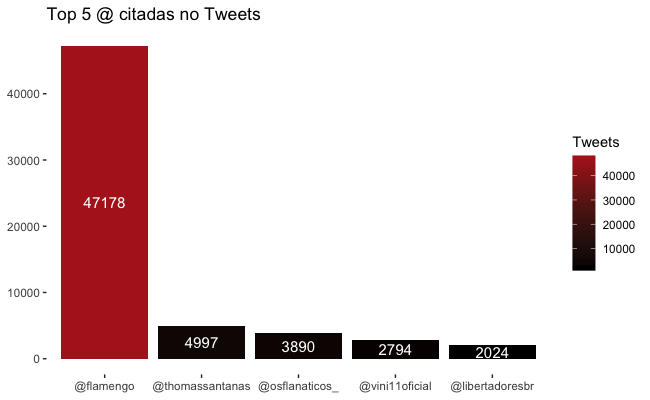
Em relação aos usuários, ou melhor, as arrobas mais citadas nos tweets. Temos o perfil oficial do Flamengo disparado, seguido pelo animado youtuber Thomas Santana que agitou o twitter durante o jogo. Cria do ninho, o bom menino Vinicius Jr também foi lembrado.
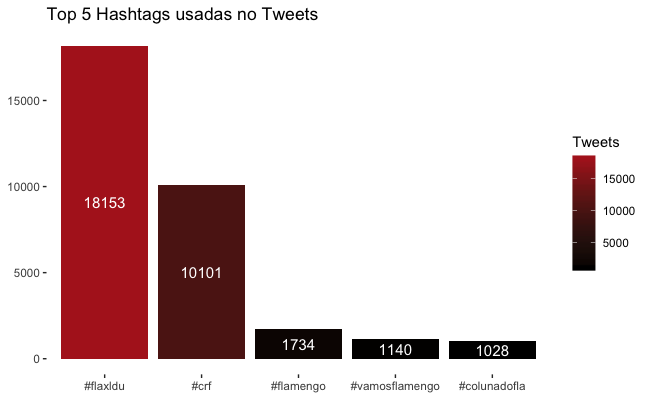
Para fechar os “Tops”, temos um top com as 5 hashtags mais usadas. Com “#flaXldu” em primeiro. Totalmente compreensível, pois foi usada pelas duas torcidas. E “#crf” em segundo, abreviação de “Clube de Regatas Flamengo” que é utilizada em todo tweet da conta oficial do time.
Finalizamos essa análise, com uma nuvem de palavras com as 100 palavras mais presentes nos tweets coletados:
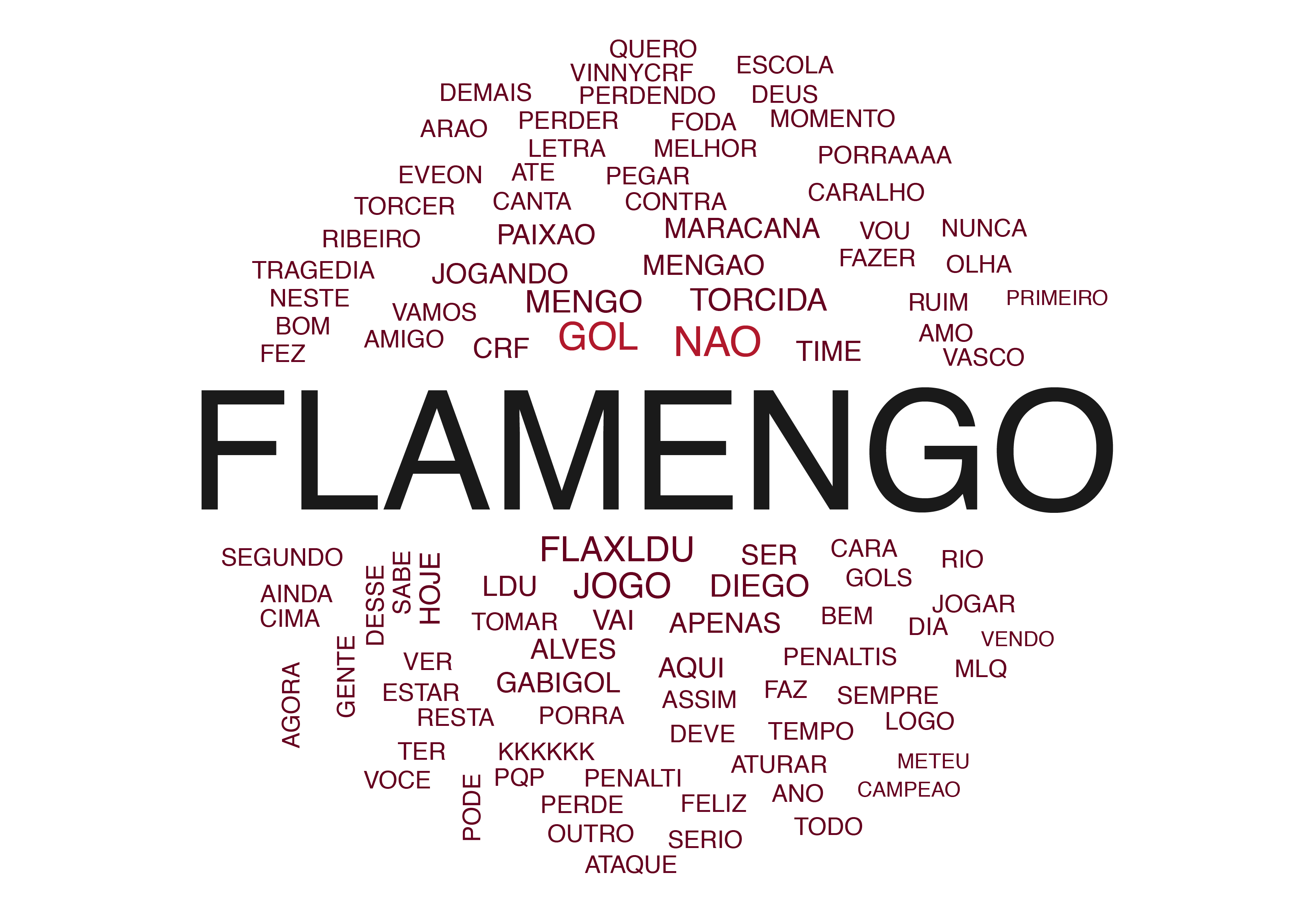
Como é possível ver, há alguns palavrões, eu optei por deixá-los pois retrata bem a montanha russa de emoções que foi o jogo. A análise termina aqui, mas sempre que possível, atualizarei o post em caso de novidades.
03-06-2019 | Update:
Tive um probleminha e acabei precisando apagar o repositório anterior. Segue o novo link do Github com o código e o dataset disponível para baixar.